随着大数据技术的演进,企业对于统一、高效且低成本的数据管理平台的需求日益迫切。传统的数据仓库与数据湖架构各有优劣,但也暴露了各自的局限性。在此背景下,结合两者优势的Lakehouse(湖仓一体)架构应运而生,正成为现代数据架构的新范式。本文将从架构核心、数据处理模式及存储服务特性三个维度,对Lakehouse进行深度解析。
一、Lakehouse架构解析:融合与统一的核心
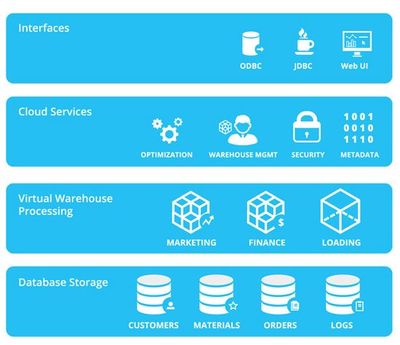
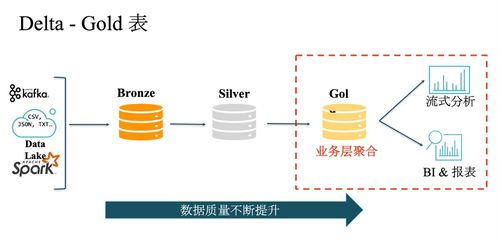
Lakehouse的核心设计理念是在低成本、高可扩展的云存储(对象存储,如S3、ADLS、OSS)之上,构建一个兼具数据湖的灵活性与数据仓库的管理性能的统一数据平台。其典型架构分为三层:
- 统一的存储层:基于云对象存储,以开放格式(如Parquet、ORC、Avro)存储原始数据、清洗后的数据以及模型数据。这解决了数据孤岛问题,实现了数据的单一副本存储,并显著降低了存储成本。
- 智能的管理与服务层:这是Lakehouse与传统数据湖的关键区别。该层通过元数据管理、事务支持(ACID)、数据版本控制、数据治理(如数据血缘、访问控制)以及索引与缓存等能力,为上层数据提供了类似数据仓库的可靠性、一致性和高性能查询基础。典型的实现如Delta Lake、Apache Iceberg和Apache Hudi。
- 多样化的计算与消费层:Lakehouse支持多种计算引擎(如Spark、Flink、Presto/Trino)和BI工具(如Tableau、Power BI)直接访问底层数据,无需复杂的数据移动和转换。这实现了批处理、流处理、数据科学与机器学习工作负载在同一数据源上的无缝运行。
二、数据处理范式:批流一体与AI/ML就绪
在数据处理方面,Lakehouse架构带来了革命性的变化:
- 批流一体处理:得益于事务日志和表格式(如Delta Log),Lakehouse能够将实时流式数据以小批量(micro-batch)或连续处理的方式,以事务性保证写入表中,使得同一张表可以同时支持历史数据分析与实时流处理,简化了Lambda架构的复杂性。
- 支持高级分析与机器学习:数据科学家和机器学习工程师可以直接在存储在Lakehouse中的原始数据或特征数据上开展工作,无需将数据导出到专用系统。这避免了数据不一致和重复存储,加速了从数据到洞察、再到模型部署的端到端流程。
- 模式演进与数据质量:通过Schema-on-Write与Schema-on-Read的灵活结合,以及内置的数据质量约束(如NOT NULL),Lakehouse在保持数据湖灵活性的提升了数据的可靠性与可管理性。
三、存储服务特性:低成本、开放与高性能
Lakehouse的存储服务特性是其竞争力的基石:
- 成本效益:核心存储采用云对象存储,其成本远低于传统块存储或数据仓库的专用存储,且具备近乎无限的扩展能力。
- 开放性与免锁定:使用Parquet等开放列式格式存储,意味着数据所有权完全属于用户,不会被任何单一厂商的计算引擎或服务锁定,促进了生态的开放与互操作性。
- 性能优化:虽然对象存储的延迟较高,但Lakehouse通过多层技术弥补:
- 元数据层优化:高效的管理层将小文件合并、建立索引、维护统计信息,使查询引擎能快速定位数据。
- 缓存与加速:支持在计算节点内存或SSD上进行数据缓存(如Delta Cache),并对热点数据进行智能分层,将热数据缓存在高性能介质上。
- 向量化执行:现代查询引擎能够直接读取列式格式,并利用SIMD指令进行向量化计算,极大提升分析查询速度。
- 企业级治理与安全:在统一的存储基础上,实现了细粒度的访问控制、数据加密(静态和传输中)、审计日志和合规性支持,满足了企业级数据管理的严格要求。
与展望
Lakehouse架构并非要完全取代数据仓库或数据湖,而是旨在提供一个融合的统一平台,以应对日益复杂的数据应用场景。它降低了架构复杂性、总拥有成本(TCO),并加速了数据价值变现的流程。随着底层表格式标准的进一步统一、查询性能的持续优化以及与云原生服务(如无服务器计算)的更深度集成,Lakehouse有望成为企业构建现代化数据栈的首选架构。其实施成功的关键在于,企业需要结合自身业务需求,审慎选择技术组件,并建立与之匹配的数据治理与文化。