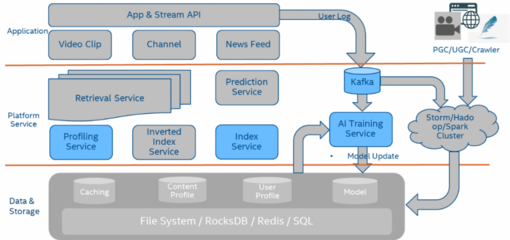
在数字化浪潮中,推荐系统已成为连接用户与海量信息的关键桥梁。面对指数级增长的用户行为数据、内容特征与实时交互信息,传统的存储与数据处理架构常陷入“信息过载”的泥潭——响应延迟、计算瓶颈、成本飙升,导致推荐效果大打折扣。如何破局?答案在于融合前沿的“存储黑科技”与智能化的数据处理服务,构建新一代推荐系统的基础设施。
一、直面“信息过载”的核心痛点
推荐系统的“信息过载”并非单纯的数据量庞大,而是体现在三大维度:
1. 数据体量爆炸:用户点击、浏览、搜索等行为日志每秒产生数百万条,历史数据累积达PB甚至EB级。
2. 实时性要求极高:用户兴趣瞬息万变,系统需在毫秒级内捕获最新行为并更新模型,实现“所见即所想”。
3. 数据结构复杂:数据包括结构化(用户画像)、半结构化(JSON日志)与非结构化(图像、视频特征向量),关联查询与融合计算挑战巨大。
传统基于磁盘的集中式数据库或Hadoop生态,在实时读写、高并发及复杂查询上往往力不从心。
二、破局利器:四大存储与数据处理“黑科技”
1. 高性能异构存储栈:分层治理,冷热分离
- 热数据层(亚毫秒响应):采用持久内存(PMem)与NVMe SSD阵列。PMem兼具内存速度与持久化特性,适合存储实时特征、高频模型参数;全NVMe SSD池则承载近期的热行为数据,支持高吞吐的实时读写,满足在线推荐引擎的低延迟需求。
- 温数据层(秒级分析):利用分布式对象存储(如Ceph)或云原生存储服务,存放历史用户行为与周期性训练数据。通过智能生命周期策略,自动将冷却数据从高速层迁移至此,平衡性能与成本。
- 冷数据层(低成本归档):采用高压缩率列式存储(如Apache Parquet)结合冰川存储服务,归档长期数据,供长期趋势分析与合规审计使用。
2. 向量数据库:激活非结构化数据的“推荐潜能”
图像、视频、文本等内容通过深度学习模型转化为高维向量。专为向量优化的向量数据库(如Milvus、Pinecone) 提供:
- 毫秒级相似性检索:基于近似最近邻(ANN)算法,从亿级向量中快速找出与用户兴趣匹配的内容。
- 动态实时更新:支持流式向量插入与索引实时重建,让新内容秒级进入推荐池。
- 多模态融合:统一存储文本、视觉、音频向量,实现跨模态内容推荐(如“听歌识影”)。
3. 实时数据湖仓一体:打破数据孤岛,统一分析
推荐系统的训练与推理需要融合历史批量数据与实时流数据。湖仓一体(Lakehouse)架构(如Databricks Delta Lake、Apache Iceberg)提供:
- 统一存储层:在对象存储上以开放格式(Parquet)存储所有原始数据与处理中间结果,消除数据拷贝与割裂。
- ACID事务与版本管理:确保数据一致性,支持模型训练的回滚与复现。
- 流批处理统一:同一套存储可同时服务Spark批量特征工程与Flink/Kafka流式实时特征计算,简化架构。
4. 智能数据处理服务:从存储到洞察的自动化管道
存储之上,云原生数据处理服务将“静默数据”转化为“推荐智慧”:
- Serverless实时计算:利用云函数(如AWS Lambda)或流处理服务(如Google Dataflow),实现无需运维的实时特征提取与用户兴趣更新。
- AI驱动的存储优化:机器学习模型预测数据访问模式,自动调整数据分层、缓存策略与索引结构,提升I/O效率。
- 隐私计算与联邦学习:采用可信执行环境(TEE)或同态加密存储,在保护用户隐私的前提下,实现跨域数据联合建模,丰富特征维度。
三、实战架构:构建面向未来的推荐数据引擎
一个典型的现代化推荐系统数据平台可分层构建:
- 接入层:日志通过Kafka/Pulsar消息队列流入,实现流量削峰与解耦。
- 实时处理层:Flink消费流数据,计算实时特征,写入向量数据库与KV存储(如Redis)供在线推理调用。
- 统一存储层:湖仓一体平台托管所有原始数据、特征仓库与模型数据,支撑批量训练与分析。
- 智能存储引擎:底层由异构存储介质(PMem、NVMe、对象存储)组成,通过智能管理平台实现自动分层、压缩与加密。
- 服务层:通过gRPC/HTTP API向推荐模型提供低延迟的数据服务,包括实时特征查询、向量检索与上下文获取。
从“存储数据”到“智理数据”
推荐系统的竞争,本质是数据利用效率的竞争。通过融合高性能存储硬件、智能数据库系统与云原生数据处理服务,我们不仅能化解“信息过载”带来的性能与成本压力,更能将数据转化为实时、精准的推荐能力。随着存算一体、神经拟态存储等前沿技术的发展,推荐系统的数据引擎将更加自主、高效,最终为用户带来“无形而恰如其分”的个性化体验。